Building a Recommendation Engine with Machine Learning
The movies we watch on streaming platforms to the products we discover in e-commerce stores.



Introduction
Ever wondered how streaming services like Netflix or e-commerce platforms like Amazon seem to know exactly what you want to watch or buy? That’s the power of recommendation engines.
These systems sift through heaps of data to deliver personalized suggestions that enhance user experience and engagement.
Why Use Recommendation Engines?

Why are recommendation engines so crucial? Simple: they increase user satisfaction and retention by offering tailored experiences. Companies use them to improve click-through rates, boost sales, and keep users engaged longer.
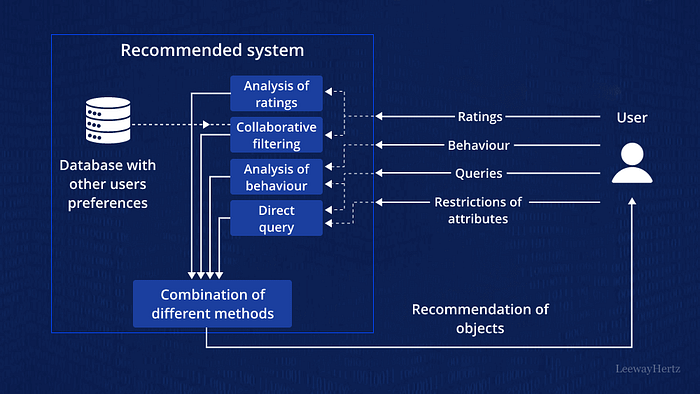
How Recommendation Engines Work
At their core, recommendation engines analyze past behavior, patterns, and preferences to make data-driven predictions about what users might like. This process involves leveraging algorithms that model relationships between users and items.
Types of Recommendation Engines
Collaborative Filtering
This approach relies on user behavior and preferences. It operates on the principle that if User A likes certain items that User B likes, they are likely to have similar tastes.
User-Based Collaborative Filtering: Recommendations are made based on the preferences of similar users.
Item-Based Collaborative Filtering: Focuses on recommending items that are similar to what a user has previously liked.
Content-Based Filtering
This type of engine uses the features of items (such as genre, keywords, or descriptions) to make recommendations. It’s like having a personalized playlist based on your listening history.
Hybrid Models
These models blend different techniques, such as collaborative and content-based filtering, to boost accuracy. They’re more complex but often yield better results by mitigating the weaknesses of using just one approach.
Key Steps to Build a Recommendation Engine
Building a recommendation system involves a series of steps:
Data Collection
Data Preprocessing
Model Selection
Training and Evaluation
Deployment and Scaling
Data Collection
Data is the backbone of any recommendation engine. Collecting user behavior data, such as clicks, likes, purchases, and ratings, helps create a robust system. Ensure your data source is reliable and diverse.
Data Preprocessing
Raw data is often messy. Preprocessing involves cleaning data, handling missing values, and formatting it into a usable structure. This step ensures that your machine learning algorithms receive input they can easily analyze.
Selecting the Right Model
Choosing the right algorithm depends on the type of recommendations you aim to make. Common algorithms include:
K-Nearest Neighbors (KNN)
Matrix Factorization
Deep Learning Models for more complex, layered analysis.
Collaborative Filtering
User-Based Collaborative Filtering

This technique finds similarities between users to suggest items that other users have enjoyed. For instance, if two people share similar viewing habits, they might enjoy the same movies.
Item-Based Collaborative Filtering
Instead of focusing on users, this method focuses on similarities between items themselves. For example, if a user liked Product A, and Product B is commonly bought together with Product A, Product B will be recommended.
Content-Based Filtering
This method looks at item features such as tags, descriptions, or metadata. For example, if a reader enjoyed an article about “Machine Learning,” content-based filtering would recommend other articles that discuss related topics.
Hybrid Models
Combining collaborative and content-based filtering results in more accurate recommendations. For example, Netflix employs a hybrid approach to enhance user experience.
Training the Model
Training involves feeding the model a dataset and allowing it to learn patterns. Algorithms such as Singular Value Decomposition (SVD) or deep learning neural networks are commonly used for training more sophisticated recommendation engines.
Evaluating the Model’s Performance
Use metrics like Mean Squared Error (MSE), Root Mean Squared Error (RMSE), or Precision and Recall to assess how well your recommendation engine is performing. This step is crucial for understanding the strengths and weaknesses of your model.
Scaling and Deployment
Once the model is trained and evaluated, the next step is deploying it. This may involve integrating the model with your web platform, using tools like TensorFlow Serving or AWS SageMaker for real-time recommendations.
Challenges in Building Recommendation Engines
Cold Start Problem
This occurs when there isn’t enough data for new users or items. Solutions include using hybrid models or relying on demographic data initially.
Data Sparsity
Sometimes, user-item interactions are too sparse to draw meaningful insights. Collaborative filtering is particularly susceptible to this issue.
Future Trends
The field is advancing rapidly, with trends like context-aware recommendation engines that consider a user’s current situation and AI-driven personalized experiences that adapt in real-time based on user behavior.
Conclusion
Building a recommendation engine is a complex but rewarding task. By understanding different types of models, data handling, and the nuances of implementation, businesses can create powerful tools that enrich user experiences and drive engagement.
Connect with us for all your IT development needs! Let’s discuss how we can bring your ideas to life — sales@codnestx.com
#RecommendationEngine #MachineLearning #AI #DataScience #PersonalizedRecommendations #TechDevelopment #MLAlgorithms #AIinBusiness
FAQs
1. What is a recommendation engine?
A recommendation engine is a system that predicts and suggests items a user may like based on past behavior or characteristics.
2. What are common types of recommendation engines?
The main types include collaborative filtering, content-based filtering, and hybrid models that combine both.
3. Why is data preprocessing important?
Data preprocessing ensures that the information fed to the model is clean, structured, and ready for analysis, improving the model’s performance.
4. How do I choose between collaborative and content-based filtering?
Collaborative filtering works best for large datasets with ample user interactions, while content-based filtering is ideal when you have detailed item descriptions.
5. What are some common challenges in building recommendation engines?
Challenges include the cold start problem and data sparsity, both of which can impact the model’s effectiveness.